
About Me

Problem Solver

Multitasking
OOAD

Teamwork
Summary
Hello, My name is Steven Roddan and I'm a Bachelor of Science in
Computer Science from Northern Illinois University. My main topics of interest
in Computer Science are Machine Learning, Operating Systems, Numerical
Analysis and Algorithms. Experience with OOAD principles and an understanding
of Agile/Scrum developement.
I'm am very interested in the whole design process of modern applications.
Ideally I would like to find a job that challenges me everyday with new topics/technology
to better myself. I enjoy being motivated to learning something new. One of my
projects mentioned below illustrates this, as I've never had a formal education on CUDA or
high performance compute. The project is aimed at numerical operations in C++. In short,
it investigates multithreading, SIMD(AVX2) and CUDA for various algorithms to compare the
pros and cons of each.
Typically when I'm not programming, you can find me playing video games,
watching documentaries/educational videos and enjoying the outdoors with friends
and family. Recently I have found a new hobby with biking trails,
so you could say I'm looking forward to the Spring/Summer.
Skills
Proficient Languages: C++(std, ~CUDA), Python(Numpy, Tensorflow/Keras), PHP,
MYSQL.
Familiar Languages: Java, C#, R, Javascript, Julia, Assembly.
Operating Systems: Windows, Linux/Ubuntu.
Developement tools: Github, Visual Studio Code, CLion, phpMyAdmin, PuTTY.
Soft Skills: Problem Solving, Motivation, Dependability, Positivity.
Projects

Propulsion
A self project aimed at studying CUDA and costly Numerical Operations.
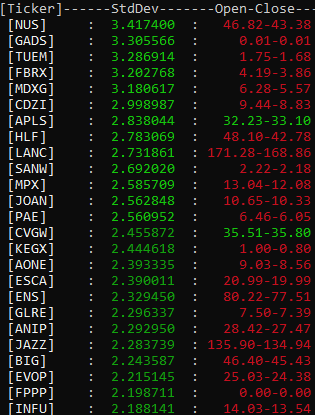
Market StdDev
A self project for calculating the Standard Deviation across 5000+ companies stocks.

RedBlack Tree
Self-balancing Binary Search Tree with average log(n) for Search/Insert/Delete.
Red Black Tree
Repo Link: https://github.com/rottenroddan/redBlackTree
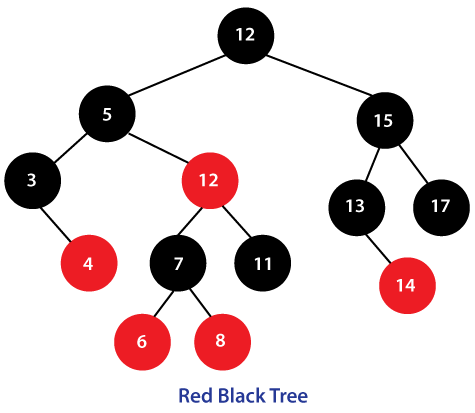
A project I started for fun after I graduated from College. Binary Search Trees have always interested me since I learned about them in an algorithms course. The Red Black Tree was a good challenge programming as far as testing and debugging.
Features
This project is like a standard Binary Search Tree from a general usage stance. Includes
all the standard functions of one like: Insert, Delete, and Search. Under the hood of this Binary Search Tree is the
behavior of a Red Black Tree which is self-balancing. The worst time complexity for any of the methods is log(n).
Overall this project was relatively easy. Implementing the delete method was the most difficult part of
this project due to many different edge cases to keep the tree self-balancing.
As I stated on the repo page, if one is to actually use this, I would recommend using C++'s built in Map
or Set if you're looking for performance and reliability.
Market Standard Deviation
Repo Link: https://github.com/rottenroddan/MarketStdDeviationCalculator
Market Std Deviation Calculator is a simple C++ program designed to calculate from over 5000 companies their current Standard Deviation from their normal line. It was a project I wanted to implement to get experience with C++ API calls using the cURL library and also as another tool to aid me with finding companies that are deviating towards their lows.
Features
This program has one main feature, along with two other settings to help maintain
accurate stock data. The main feature is to calculate the Standard Deviation from all the tickers included
in the tickers directory. These files contain all the candle information for their respective ticker file
name. The last part of this feature is displaying the top results of the tickers that are deviating below
their normal line. Along with displaying how much in order these stocks are deviating.
The last two features are for maintaining the stock data. The first one is generating ticker
files from TDAmeritrades API. This requires a developer key you will need to get from them. This is
limited as the key is free and not payed for, so for this function to run, it takes roughly an hour
to generate data for 5000 stocks since the API calls are limited to 60/min. The last feature is a
simple "try to fix" ticker. It goes through the directory and looks for any files that may be empty.
When I was testing, some(very few) of the API calls were coming back empty handed. Either due a heavy
load on the backend or some inconsistent problem on my end. Therefore the this function looks for empty
files and tries to fix them. Most tickers that had empty files aren't available on TDA so hence their
data doesn't exist from the tickers.txt file.
Future
For the most part, this project is wrapped up. I might comeback and use this
projects data as an example of Machine Learning on the Propulsion project, but overall that would just be
using bits from this project rather than the data generated on its main goal. The goal of project was
achieved, therefore I am happy with it, as far as keeping the code neat and efficient and to the point.
I definitely feel using C++ for this was wasteful, as Python would of been the best choice for this
small project. However I knew that from the start knowing the goal was learning how to incorporate a static
linked library like cURL.
Propulsion
Repo Link: https://github.com/rottenroddan/Propulsion

Image of Mandelbrot above the main disk with period 8. Image was generated via the Mandelbrot class with 1500 iterations per pixel value.
Propulsion, was a Numerical/CUDA project I started before my final semester in the fall
of 2020. The project (being a self-project) has gone through many technical changes as more
research has been done on paticular subjects. Firstly, I'd like to mention this project is not
meant to rival libraries like cuBLAS or Boost. It is simply created to apply my understanding,
analyze and research more about the numerical operations that have a huge impact in todays algorithms
like Machine Learning/Artificial Intelligence.
In the start, I was mostly focused on creating CUDA Kernels to solve simple matrix operations
like addition/subtraction/schurs product. As I got the hang of using CUDA from samples provided online,
I started looking more at the numerical operations that would benefit Machine Learning the most. From this
point on, I started creating a Matrix class with various methods to support numerical operations. This
class also uses smart pointers to handle memory. You can see more on my Github about all the various methods.
Matrix Dot Product
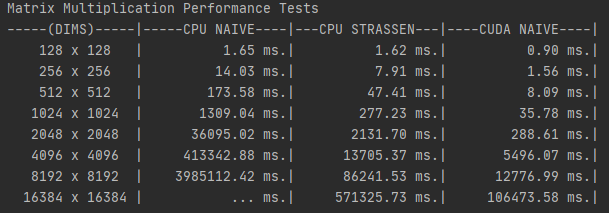
Image of original dot product tests with paged memory for all methods.
Above are the results of a controlled dot product test on various
sized square matrices. You can see right away that the Naive CPU method is very slow for large matrices.
I actually skipped the 16384x16384 test for CPU NAIVE as it would of took ~10 hours to complete.
Importantly, note while Strassen Multiplication was beat in all cases against CUDA, it has better
time complexity than CUDA as it requires less multiplications than the naive method. You can
see that in theory, this method is much faster. However, the results are skewed as the Strassen Method only uses
7 threads at any given time. While CUDA is 1024 light-weight threads... Even the testing data is suited well
for Strassen multiplication, as they're all square matrices of 2^N size, which allows for no time spent padding
the matrix to an even number or rows/cols.
As of 3/17/2021, I have successfully updated the Matrix class to handle paged memory allocations and
pinned memory allocations using unique_ptr to handle the lifetime of the Matrix itself. Originally after
refactoring my code, it seemed that CUDA pinned memory wasn't disadvantageous as I thought, until methods
like Strassen Multiplication were tested upon. Since I was using to cudaMallocHost to allocate an array, which
is notoriously slow if called frequently, this created the below results:
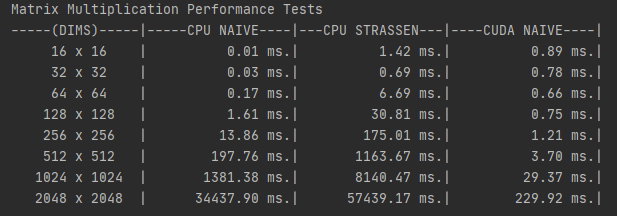
Image of dot product tests with pinned memory for all methods.
Above, you can see the difference that pinned memory had on the Strassen
dot product. The naive CPU method is much faster even though it has worse time complexity. This is due to
cudaMallocHost being called many times since this method relies on Matrix Constructors to allocate more memory.
This prompted me with another design change, which is to incorporate pinned memory and paged memory in this class.
The Matrix class would inherently be pinned memory, unless specified as paged via a parameter in the constructor.
Results with Paged for CPU and Pinned for CUDA below:
I have future plans to return to Matrix Dot Product to further optimize the CUDA kernels as the naive kernel does not take full advantage of the my GPU as other sources suggest.
Tensor Operations
This class is currently mostly work in progress. Uses packed template arguments to allow
the user to build an any size dimension tensor. The tensor class contains a container which holds unique pointers to
Matrices. Since the operations I'm dealing with, I found it beneficial to just reuse the Matrix class rather than
creating a new array of values.
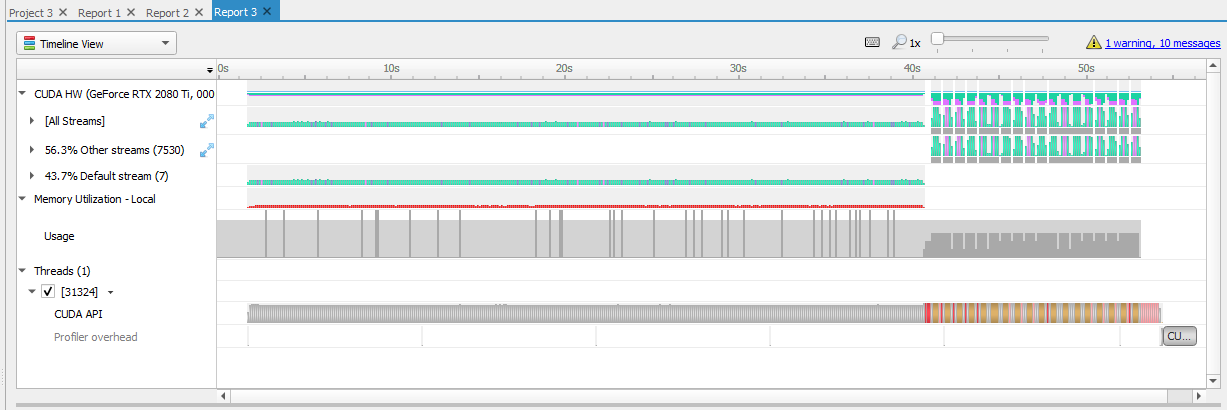
Firstly, I was able to utilize CUDA's streams to create async copies and kernel launches. Along with less overhead,
Tensor::cudaAdd was able to achieve a 3x performance gain on my original implementations. Below you can see the Nsight data.
For the first ~40s, 6 additions are done on two Tensors of size (5.76GB). This naive method doesn't use streams, and therefore
a lot of time is wasted on non-sync memory transfers. From 41s on, streams is enabled for 6 Additions of the same 5.76GB
of data. This method is clearly faster as the 6 additions finish in 13s vs ~40s. You can see more on my Github on how I implemented this!
Mandelbrot Set
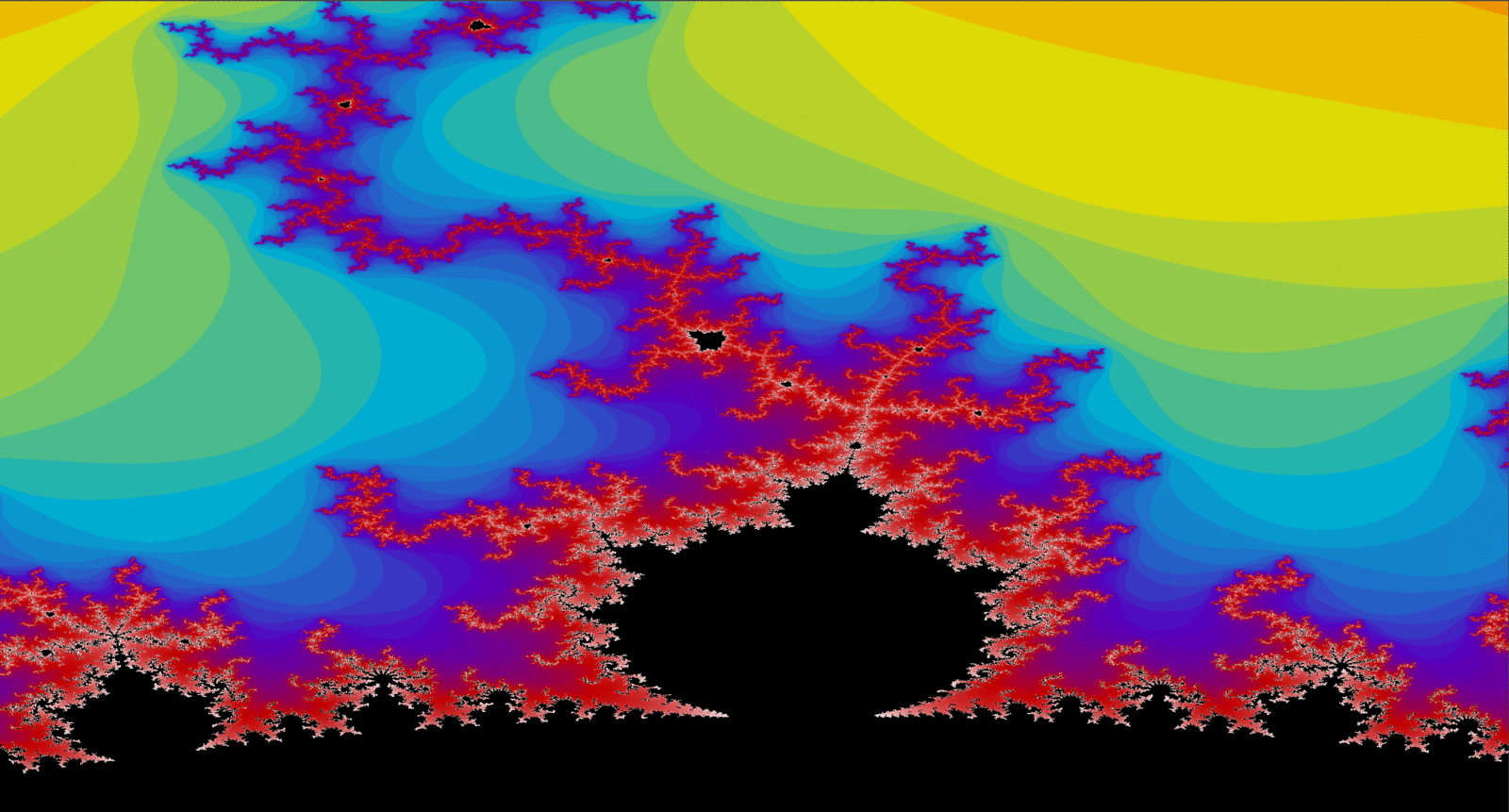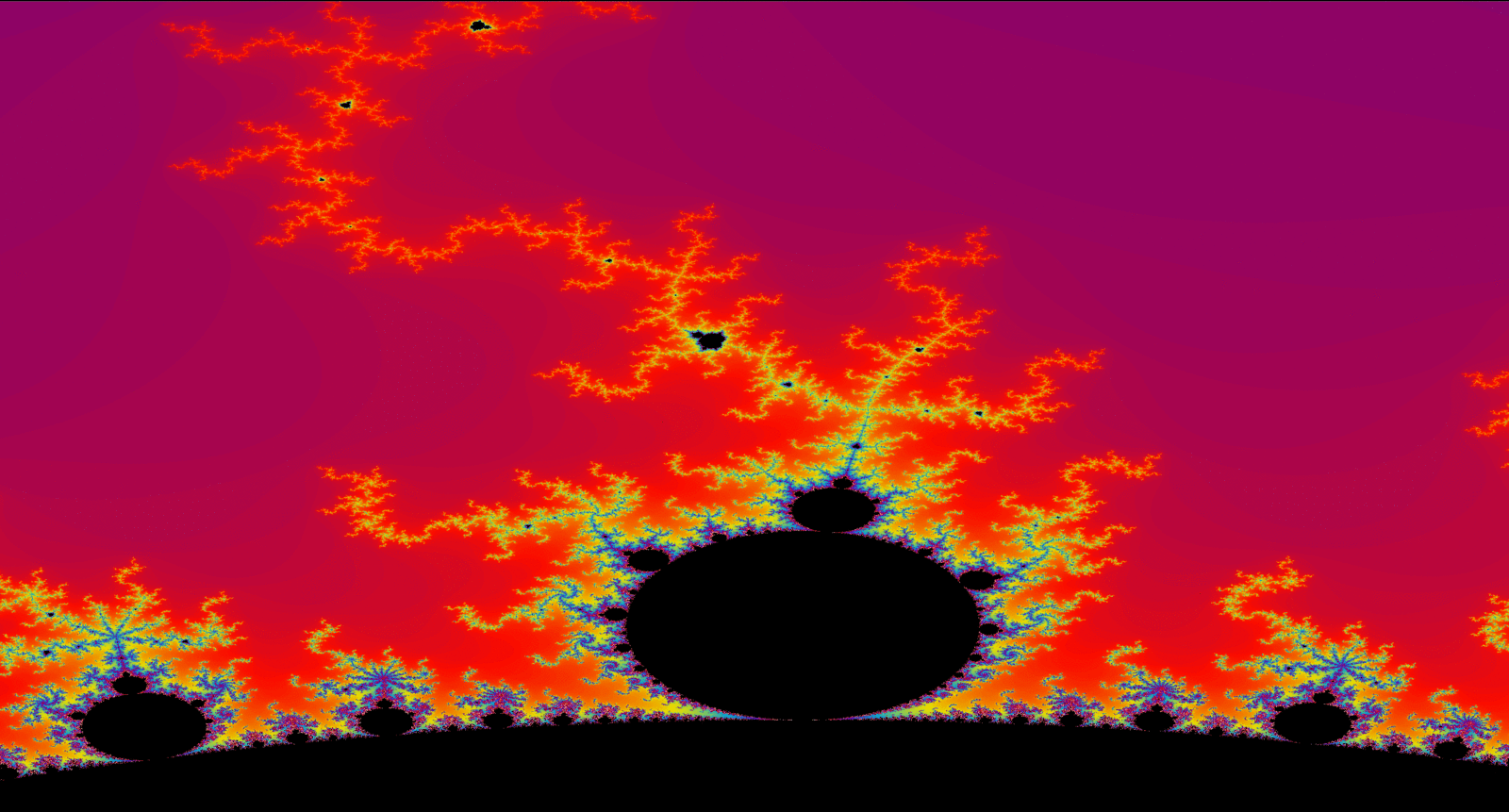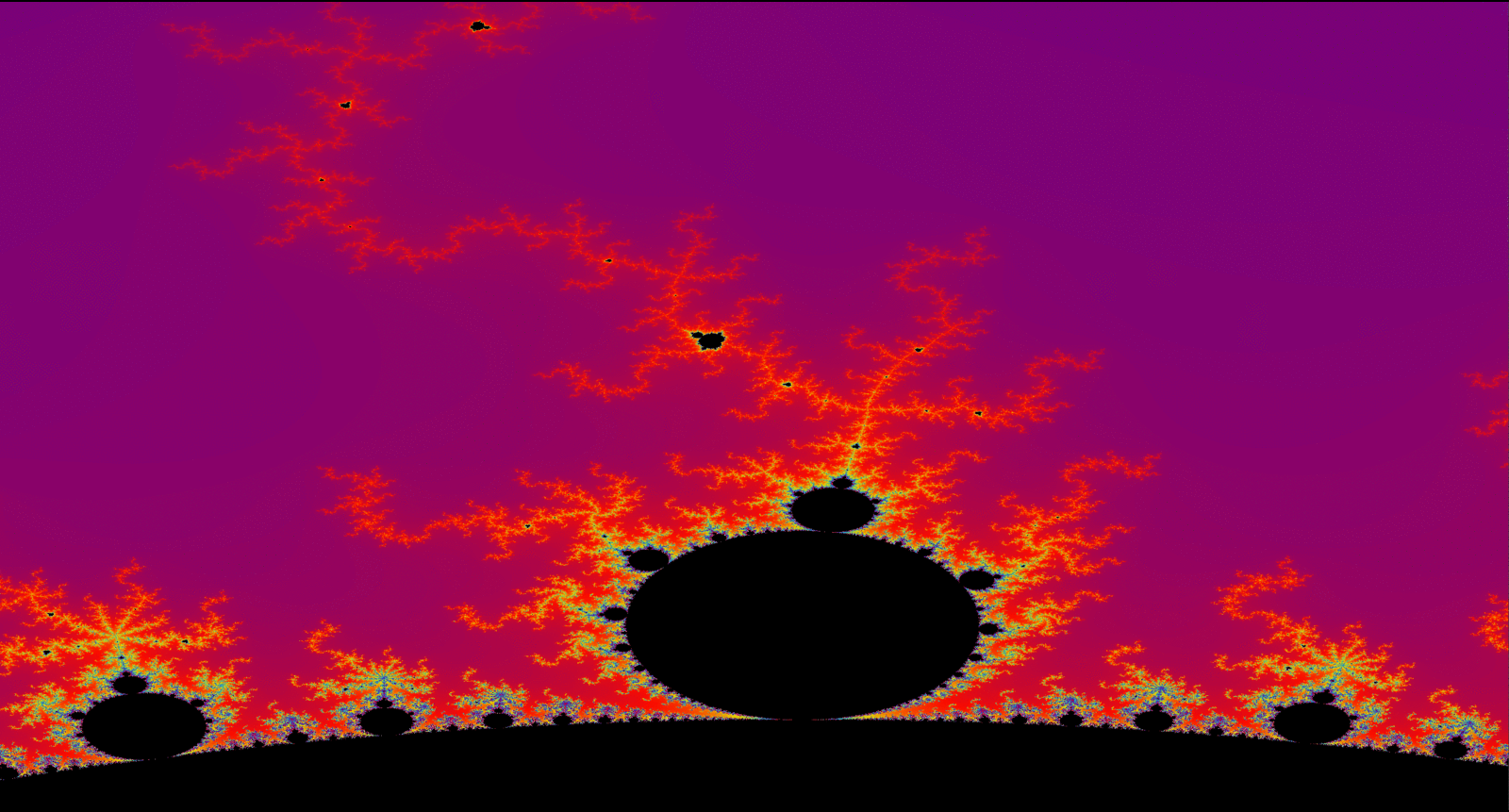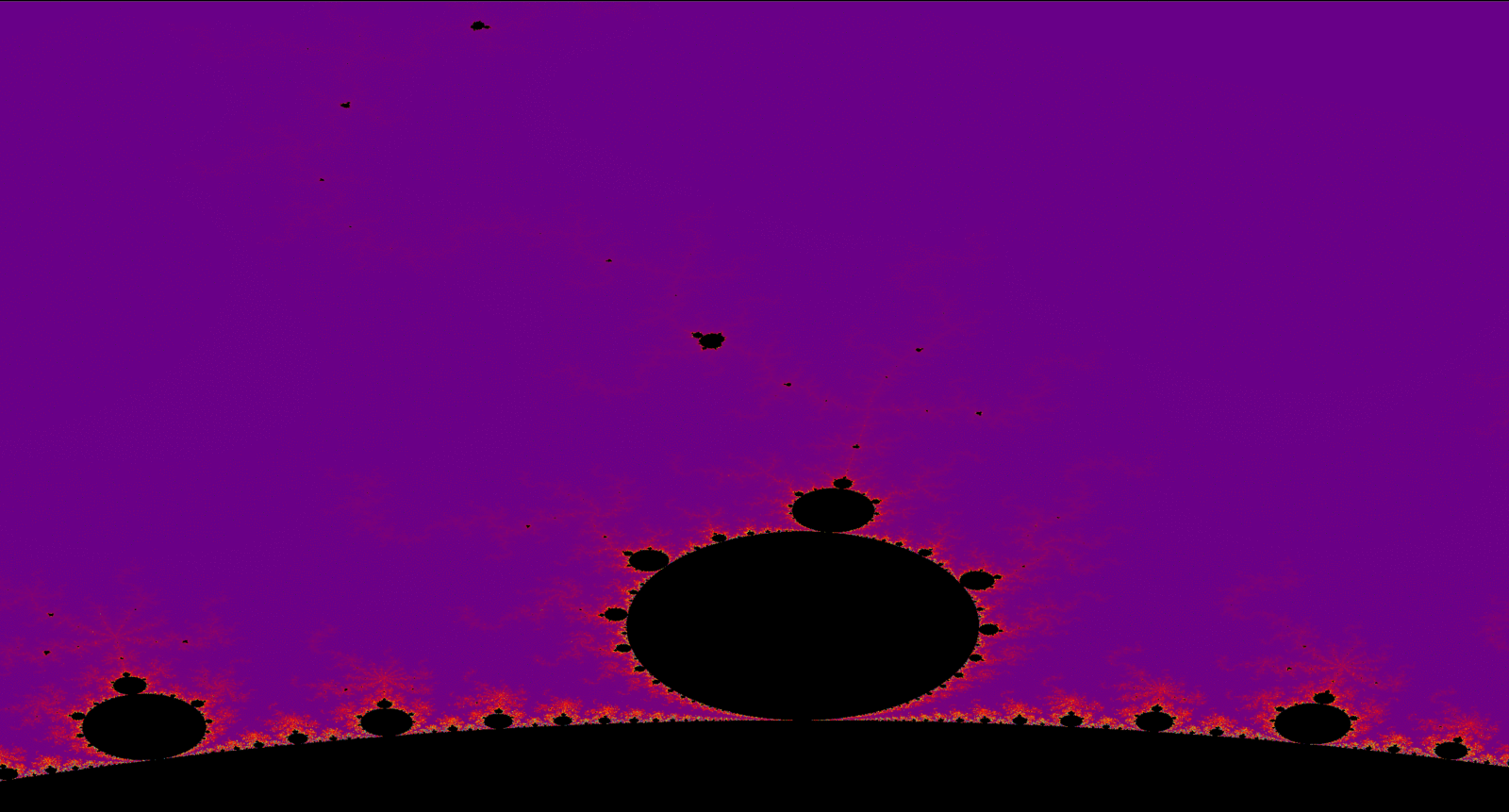
The above image starts from 125 itterations -> 250 -> 500 -> 1,000 -> 1,500 -> 2,000 -> 5,000 -> 10,000 -> 20,000.
Propulsion also has another class "Mandelbrot", which is a simple class
that uses the Matrix class I designed to help implement a visualization of the Mandelbrot set on windows.h
API. This part of the project was more of showing off the various optimizations I could perform
on the Mandelbrot Set using CPU driven SIMD instructions(AVX2 in my case).
Above, you can see the Mandelbrot change from smeared shades of colors to more fine in detail. Due to
total calculations per pixel in the Mandelset is increased, thus getting a more accurate depiction of the
fractal. This part of the project was just a for fun topic I always wanted to learn how to implement. Below are
the performances for various methods of calculating.
| Compute Method | Avg Time To Complete | Iterations Per Pixel |
|---|---|---|
| 1 Thread Naive | 3.121s | 10K |
| 1 Thread AVX2 | 1.083s | 10K |
| 8 Thread AVX2 | 0.543s | 10K |
| 16 Thread AVX2 | 0.350s | 10K |
| CUDA | 0.040s | 10K |
The above tests were generated on a zoomed part on the main bulb. Results vary greatly depending on the position of
of the Mandelbrot set, as some groups of pixels are finished in less clock cycles than others. Ran on a i9-9900k and Nvidia 2080ti.
Mandelbrot could get a ridiculous speed increase if I chose to use OpenGL to render the image on screen,
as currently it is being calculated on CUDA, then copied back to host, which then uses Windows to draw the image
on the screen.